目录
About Software Testing:
1、Speed and Performance of Parserless and Unsupervised Anomaly Detection Methods on Software Logs
Type: Paper
Abstract: Software log analysis can be laborious and time consuming. Time and labeled data are usually lacking in industrial settings. This paper studies unsupervised and time efficient methods for anomaly detection. We study two custom and two established models. The custom models are: an OOV (Out-Of-Vocabulary) detector, which counts the terms in the test data that are not present in the training data, and the Rarity Model (RM), which calculates a rarity score for terms based on their infrequency. The established models are KMeans and Isolation Forest. The models are evaluated on four public datasets (BGL, Thunderbird, Hadoop, HDFS) with three different representation techniques for the log messages (Words, character Trigrams, Parsed events). For training, we used both normal-only data, which is free of all anomalies, and unfiltered data, which contains both normal and anomalous instances. We used primarily the AUC-ROC metric for evaluation due to challenges in setting a threshold but we also include F1-scores for further insight. Different configurations are advised based on specific requirements. When training data is unfiltered, includes both normal and anomalous instances, the most effective combination is the Isolation Forest with event representation, achieving an AUC-ROC of 0.829. If it's possible to create a normal-only training dataset, combining the Out-Of-Vocabulary (OOV) detector with trigram representation yields the highest AUC-ROC of 0.846. For speed considerations, the OOV detector is optimal for filtered data, while the Rarity Model is the best choice for unfiltered data.
Source: https://cs.paperswithcode.com/paper/efficiency-of-unsupervised-anomaly-detection
GitHub: https://github.com/evotestops/loglead
2、A K-Means Based Clustering Approach for Finding Faulty Modules in Open Source Software Systems
Type: Paper
Abstract:
Prediction of fault-prone modules provides one way to support software quality engineering. Clustering is used to determine the intrinsic grouping in a set of unlabeled data. Among various clustering techniques available in literature K-Means clustering approach is most widely being used. This paper introduces K-Means based Clustering approach for software finding the fault proneness of the Object-Oriented systems. The contribution of this paper is that it has used Metric values of JEdit open source software for generation of the rules for the categorization of software modules in the categories of Faulty and non faulty modules and thereafter empirically validation is performed. The results are measured in terms of accuracy of prediction, probability of Detection and Probability of False Alarms.
Source:
My understanding:
1)Purpose: The method aims to predict fault-prone modules by clustering based on code metrics such as coupling, cohesion, depth of inheritance, and number of children. These metrics serve as indicators of structural quality and help in pinpointing potentially problematic sections within software modules.
目的:该方法旨在通过基于代码指标(如耦合、内聚、继承深度和子级数量)的聚类来预测易出错的模块。这些指标作为结构质量的指标,有助于查明软件模块中可能存在问题的部分。
2)Data Source: JEdit, an open-source Java-based text editor, serves as the dataset for this study. By clustering modules from JEdit, the researchers seek to create fault detection models applicable to other open-source systems.
数据来源:JEdit 是一个基于 Java 的开源文本编辑器,是本研究的数据集。通过对 JEdit 的模块进行聚类,研究人员试图创建适用于其他开源系统的故障检测模型。
3)Methodology: After computing the selected metrics, the dataset undergoes feature selection to isolate the most predictive attributes. Then, clustering is performed using K-means with both Euclidean and Manhattan distances. The two distances help in comparing centroid calculations—Manhattan distance using median instead of mean minimizes sensitivity to outliers.
方法论:计算所选量度后,数据集将进行特征选择,以隔离最具预测性的属性。然后,使用具有欧几里得距离和曼哈顿距离的 K-means 执行聚类分析。这两个距离有助于比较质心计算 - 使用中位数而不是平均值的曼哈顿距离可最大程度地降低对异常值的敏感度。
4)Evaluation: The study employs a confusion matrix to assess the classification accuracy of the clustering method. It evaluates the model's effectiveness based on the detection probability (specificity) and false alarm rate (incorrectly identifying fault-free modules as faulty).
评估:该研究采用混淆矩阵来评估聚类方法的分类准确性。它根据检测概率(特异性)和误报率(错误地将无故障模块识别为故障)来评估模型的有效性。
5)Conclusion: Results indicate the K-means clustering method is a feasible approach for identifying fault-prone modules, with reasonable accuracy, and is adaptable to object-oriented systems.
结论:结果表明,K-means 聚类方法是识别易故障模块的可行方法,具有合理的准确性,并且适用于面向对象的系统。
3、Test Case Prioritization Using Requirements-Based Clustering
Type: Paper
Abstract: The importance of using requirements information in the testing phase has been well recognized by the requirements engineering community, but to date, a vast majority of regression testing techniques have primarily relied on software code information. Incorporating requirements information into the current testing practice could help software engineers identify the source of defects more easily, validate the product against requirements, and maintain software products in a holistic way. In this paper, we investigate whether the requirements-based clustering approach that incorporates traditional code analysis information can improve the effectiveness of test case prioritization techniques. To investigate the effectiveness of our approach, we performed an empirical study using two Java programs with multiple versions and requirements documents. Our results indicate that the use of requirements information during the test case prioritization process can be beneficial.
Source: https://ieeexplore.ieee.org/abstract/document/6569743
4、Software Fault Prediction Using Quad Tree-Based K-Means Clustering Algorithm
Type: Paper
Abstract: Unsupervised techniques like clustering may be used for fault prediction in software modules, more so in those cases where fault labels are not available. In this paper a Quad Tree-based K-Means algorithm has been applied for predicting faults in program modules. The aims of this paper are twofold. First, Quad Trees are applied for finding the initial cluster centers to be input to the A'-Means Algorithm. An input threshold parameter δ governs the number of initial cluster centers and by varying δ the user can generate desired initial cluster centers. The concept of clustering gain has been used to determine the quality of clusters for evaluation of the Quad Tree-based initialization algorithm as compared to other initialization techniques. The clusters obtained by Quad Tree-based algorithm were found to have maximum gain values. Second, the Quad Tree- based algorithm is applied for predicting faults in program modules. The overall error rates of this prediction approach are compared to other existing algorithms and are found to be better in most of the cases.
Source: https://ieeexplore.ieee.org/abstract/document/5963674
My understanding:
1)Research Background and Motivation:
本研究解决了在没有标签故障数据的情况下预测程序模块中的软件故障的难题。传统的故障预测方法通常需要有标签的数据来进行监督学习。本文提出了使用无监督学习下的Kmeans算法来克服这一限制。
2)Objectives and Research Questions:
(1)开发一种基于四叉树的K-Means聚类初始化方法,为聚类分配合适的初始中心。
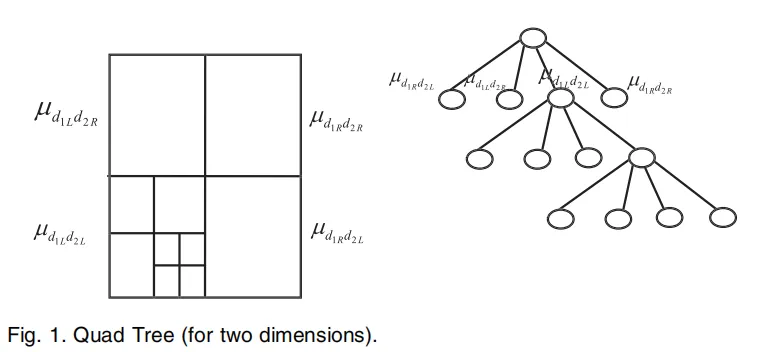
(2)应用此方法进行程序模块的软件故障预测。该方法允许用户通过调整阈值参数控制初始聚类中心的数量,以实现高效聚类并减少错误。
3)Theoretical Framework and Literature Review
之前的研究使用聚类技术和基于专业人员的方法来将软件模块标记为易出错。然而,这些方法严重依赖于人类专家的能力,而这并非总是可行的。本文通过使用四叉树自动化K-Means聚类的初始化阶段,进一步改进了先前的研究,旨在提高聚类精度并减少对专业人员的依赖
4)Methodology
基于四叉树的K-Means算法通过递归地将数据空间分成四个象限来初始化聚类中心,从而分配反映数据分布的初始中心。此方法减少了异常值的影响,并降低了K-Means算法对噪声的敏感性。实验评估将该方法与其他初始化技术进行了比较,评估了错误率、聚类增益和预测准确性。
5)Results and Findings
实验结果表明,基于四叉树的K-Means算法在故障预测方面优于传统方法,在大多数数据集中实现了较低的错误率。该算法还表现出较高的聚类增益值,表明聚类质量较高。四叉树初始化提高了K-Means聚类在故障预测中的鲁棒性和准确性。
6)Discussion and Interpretation
研究结果表明,基于四叉树的初始化方法在没有标签数据的故障预测场景中有效。通过自动化初始聚类分配,该方法解决了K-Means算法的挑战,例如对初始中心和噪声的敏感性,使其成为无监督故障预测的可行替代方案。
7)Limitations and Future Directions
该研究指出了潜在的局限性,包括对阈值参数的依赖性,这会影响聚类结果。未来的研究可以探索优化此参数,并在更多样化的软件数据集中应用该方法,以评估其通用性。
8)Conclusion
本文提出了一种新颖的基于四叉树的K-Means聚类算法,增强了无监督的软件故障预测。研究表明,该方法能够有效地根据故障可能性对程序模块进行聚类,成为在缺乏标签数据的场景中监督故障预测模型的替代方案。
本文作者:Reeshiram
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!